Building My Own LLM Council
I’m excited to share my own take on LLM Council: a project where multiple language models can review the same prompt, respond, and be evaluated side by side.
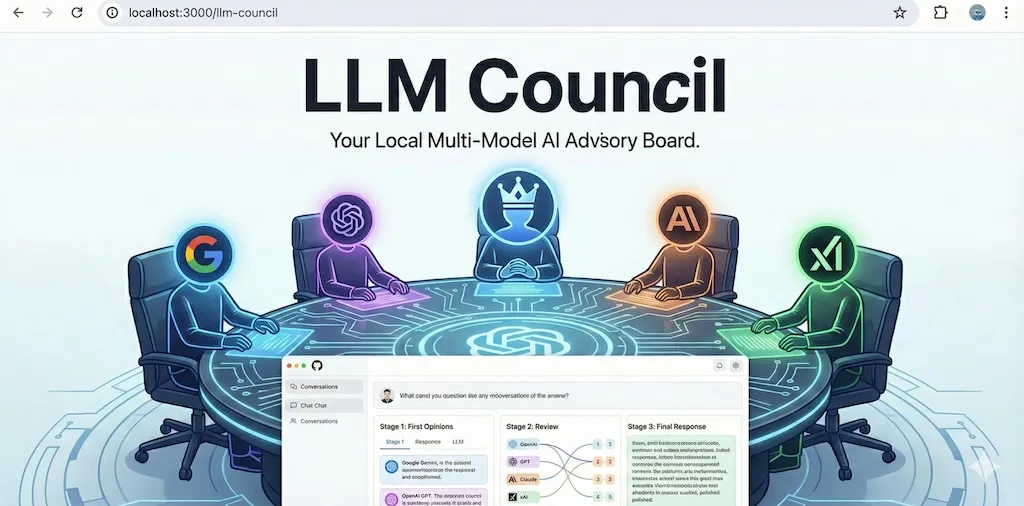
What I Built
I created my version of LLM Council to make model comparison practical and transparent. Instead of testing models one by one, this setup helps surface differences in reasoning quality, style, and consistency in a single workflow.
It’s designed for fast iteration so I can run the same tasks across multiple models, inspect outputs, and improve prompts with clearer feedback loops.
Check Out the Project
You can explore the code here:
Why I Made It
I wanted a clean way to evaluate model behavior beyond quick one-off tests. Having a council-style view makes it easier to:
- Compare strengths and weaknesses across models
- Spot hallucinations and inconsistencies earlier
- Improve prompts based on multi-model feedback
- Build confidence before shipping AI features
What’s Next?
I’ll keep expanding this project with more evaluation scenarios and workflows. If you’re experimenting with model benchmarking or prompt engineering, this repository should be a useful starting point.