
My MSc AI Thesis: Efficient Cross-Task Distillation for Trajectory Prediction
I recently defended my MSc AI thesis at Vrije Universiteit Amsterdam:

Efficient Cross-Task Knowledge Distillation for Map-Matched Trajectory Prediction: Matching SOTA Performance through Representation Alignment
The thesis asks a practical question for mobility AI systems:
Can we transfer the spatial reasoning of a large transformer model into a smaller, deployment-friendly trajectory generator without paying transformer-level inference cost?
Problem I Worked On
Urban trajectory generation is useful for traffic simulation, digital twins, and planning — but production systems need models that are both realistic and efficient.
In this project, I focused on two models with very different strengths:
- HOSER (student): compact and efficient trajectory generation on road-segment graphs
- LM-TAD (teacher): larger transformer-based anomaly detector that captures strong spatial “normalcy” patterns
The core challenge was that these models operate in different output spaces (road segments vs. grid tokens), so standard logit-level distillation does not apply directly.
What I Built
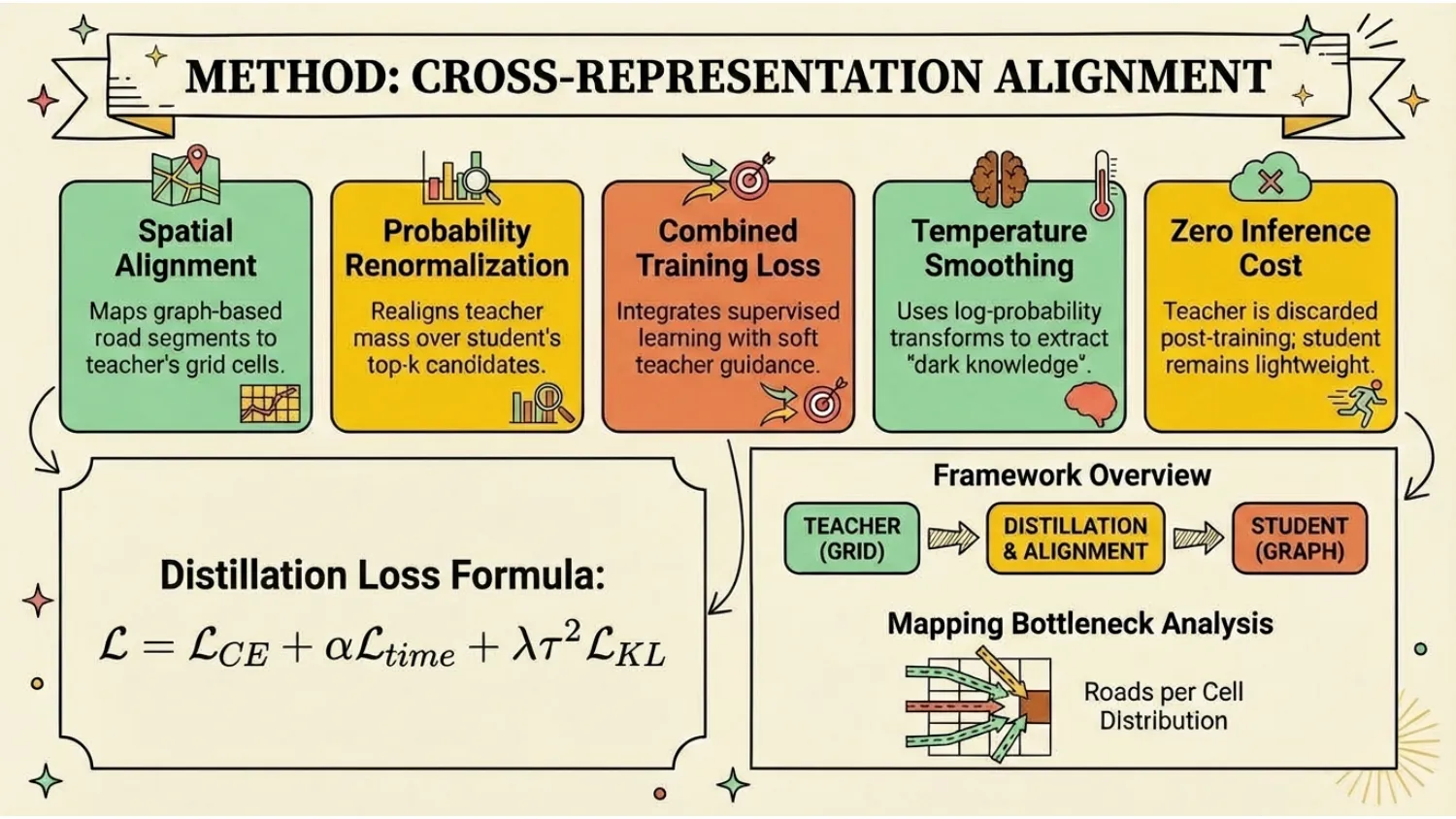
I designed and implemented an end-to-end cross-task distillation framework with four key pieces:
-
Cross-representation alignment
- Mapped road segments to teacher grid cells
- Renormalized teacher probability mass into the student’s candidate-road space
-
Training-time distillation, zero inference overhead
- Teacher used only during training
- Deployed student architecture unchanged at inference
-
Hardware-efficient training pipeline
- Mixed precision
- Vectorized mapping/collation
- GPU-accelerated lookup operations
- Throughput-oriented batching and memory-aware engineering
- The entire software and hardware stack utilized PyTorch and CUDA, with custom HOSER and LM-TAD models that I specifically optimized for efficiency, enabling them to run even on household hardware.
-
Reproducible evaluation framework
- Controlled vanilla vs distilled comparisons under identical settings
- Multi-metric evaluation (JSD, Hausdorff, DTW, EDR, OD completion)
- Train-OD vs Test-OD analysis to separate memorization from generalization
Results and Findings
Across Beijing and Porto benchmarks, the distilled student matched the strong vanilla baseline on key metrics while preserving deployment efficiency.
Key findings:
- Distillation was technically feasible despite heterogeneous model representations
- In clean benchmark regimes, distillation produced parity rather than large gains
- Many-to-one mapping collisions and limited teacher separability constrained improvement headroom
- Scenario-level analysis suggested only modest, context-dependent gains (e.g., some suburban/peak slices)
From an engineering perspective, this is still a strong result: it validates a robust distillation design under real compute constraints and shows where cross-task transfer helps versus where inductive bias already dominates.
Why This Matters
This thesis demonstrates how I work on ML systems end-to-end:
- Turning research hypotheses into implemented, testable pipelines
- Handling non-trivial representation mismatches between models
- Making advanced methods practical on commodity hardware
- Reporting results rigorously, including negative or parity outcomes
I care about building AI systems that are not only novel, but also reproducible, efficient, and honest about where value actually comes from.